Choose timezone
Your profile timezone:
13th GPU Day - Massive parallel computing for science and industrial application
The 13th GPU Day will organized by the Wigner Scientific Computation Laboratory, Wigner RCP from May 15-16, 2023 at the Wigner Datacenter in the KFKI Campus.
The GPU Day is a annualy organized international conference series dedicated to massively parallel technologies in scientific and industrial applications since a decade. It’s goal is to bring together from academia, developers from industry and interested students to exchange experiences and learn about future massively parallel technologies. The event provides a unique opportunity to exchange knowledge and expertise on GPU (Graphical Processing Unit), FPGA (Field-Programmable Gate Array) and quantum simulations. As in previous years, we are expecting 80+ participants in person and online as well.
For the earlier events see: 2022, 2021, 2020, 2019, 2018, 2017, 2016, 2015, 2014
Participation is free for students, members of academic institutions, research centers, and universities.
The registration fee is 300EUR or 120.000HUF. Participants can pay via bank transfer or card at the registration desk.
ZOOM Link: https://cern.zoom.us/j/65039948213?pwd=RzNmcFFPN0JqdWl3RjNaZnFRKy9Edz09
YouTube Link (Monday): https://youtube.com/live/Q_OnI2_uFLM?feature=share
YouTube Link (Tuesday): https://youtube.com/live/-7GwjRsJElQ?feature=share
Confirmed keynote speakers
The conference will be held in offline form and there are limited places to participate personally on-site. We encourage our former, current and future partners to contribute on the conference. Contributions to the conference are welcome.
Important deadlines
Talk submission deadline: 2023 May 1
More information is available on gpuday.com
Useful pieces of information for sponsors.
Organizers:
Gergely Gábor Barnaföldi
Gábor Bíró
Balázs Kacskovics
Balázs Endre Szigeti
Zoltán Zimborás
We would like to present a short introduction to the ALICE Analysis Facility and WSCLAB projects in our datacenter. After introducing the ALICE Analysis Facility, we are discussing the corresponding IT infrastructure design and capacity in detail.
Hardware components are aging, so monitoring is an important method to keep infrastructure healthy and to prolong cluster lifetime.
We selected a monitoring solution fitting for these environments. We created server types (worker node, storage) and defined entities in our monitoring system. In some cases, monitoring checks are just basic, others are advanced and some are even more complex to make sure we know the most important details in almost real time.
We created a separate VLAN network for monitoring in order to minimize interference with real worker node traffic.
Power consumption and electricity bills are important factors nowadays. In order to see the details, we are using a visualization solution for power usage statistics based on each rack.
To scale up the monitoring system efficiently, we are using automation tools for node preparation and installation.
Historical data is also very valuable, so we integrated a database solution into our monitoring workflow.
Our roadmap for future developments includes: continuous disk tests (S.M.A.R.T.), scheduled backup for monitoring data, proper alerting based on pre-defined warning and critical levels, iterative time-based optimization for running checks, HTCondor service monitoring, monitoring GPU RAM, GPU-utilization and temperature for GPULAB and smart alerting for complex cases.
Following major upgrades of the ALICE detector during the second long shutdown, the data-taking capabilities increased by two orders of magnitude. Consequently, the ALICE distributed infrastructure was improved to enable analysis on exceptionally large data samples and to optimise the analysis process. This was carried out by developing new tools for Run 3, O2 and Hyperloop. The O2 analysis framework allows for distributed and efficient processing of the new amount of data, while the Hyperloop train system, fully integrated with O2, enables distributed analysis on the Grid and dedicated analysis facilities. Hyperloop was developed using Java, JavaScript and a modern versatile framework, React. This allowed the implementation of responsive and adaptable features facilitating the user experience. The new train system has already been in use since the start of Run 3, with extensive documentation available. This talk will discuss the requirements and the used concepts, providing details on the actual implementation. An overview of the current status of the analysis in Run 3 will also be presented.
Mirages (fata morgana) can appear for example above water bodies in our natural environment, when certain atmospheric conditions are satisfied, e.g. the water is warmer than the ambient air, creating a near-surface temperature-gradient resulting in a quick variation of the refractive index of air. The size of the visible mirage carries information on the overall difference in temperature. Extracting it requires one to have a complex deconvolution based on various environmental parameters, which poses a challenge in case of a general application. Here, we developed a machine learning based tool to extract the temperature difference information from photographs taken of mirages.
Hastlayer (https://github.com/Lombiq/Hastlayer-SDK) is an open-source tool to increase the performance and decrease the power consumption of .NET applications by accelerating them with FPGAs. It converts standard .NET Common Intermediate Language (CIL) bytecode into equivalent VHDL constructs which can be implemented in hardware. The cloud-available Xilinx Alveo family of boards are supported for high-performance use-cases, as well as the Zynq 7000 family of FPGA SoC devices for low-power embedded systems like drones and nanosatellites. In this talk, we'll introduce Hastlayer and how it can be used, our results showing up to 2 orders of magnitude speed and power efficiency increases, as well as the collaboration partners we seek from academia and other industry players.
Research infrastructures play key role in large-scale and collaboration researches. Each country should have its own network of these. In Hungary recently a list of the top 50 research infrastructures was put together in close connection with the researcher community. How can these help to participate in international collaborations? How can they be best utilised by the researchers? The presentation will provide an insight to a recent best practice answering these questions.
The talk wil highlights some works of the Department of Computational Sciences: new advances in the analysis of interaction of systems, in particular causal discovery. Towards the end a new initiative, the foundation of the Society of Scientific Computing will be announced.
Introduction of Virtual Institute of Scientific Computations
We give a short introduction to a new Hungarian online community dedicated to GPU programming. Our aim is to connect developers and researchers speaking Hungarian to get to know each other and be able to discuss, learn and share expertise in GPU technologies, programming, and related fields, including computer graphics, education, and more.
Recently, employing photonic quantum computers for machine learning purposes has gotten more attention, hence the need for efficient simulation of photonic quantum machine learning is key in this research area. To ease simulation, automatic differentiation of photonic quantum circuits is essential, for which a Piquasso implementation is presented.
Cystic fibrosis (CF) is a hereditary disorder caused by mutations in the cystic fibrosis transmembrane conductance regulator (CFTR) protein, resulting in the loss of function of this ion channel in the plasma membrane of epithelial cells. CFTR is composed of two transmembrane domains and two intracellular nucleotide-binding domains (NBDs), with the disordered R-domain wedged between them. Phosphorylation of the R-domain is a prerequisite for the opening of the channel, causing it to dissociate from the NBDs. Understanding the mechanism of different mutations requires knowledge of the protein structure. However, with over 350 known CF mutations, it is unfeasible to develop a treatment for all rare mutations. To address this challenge, we propose a general molecular-level intervention to facilitate activation of the channel. By designing a "miniprotein" that binds to the R-domain and inhibits its insertion between the two NBDs, an increase in CFTR activity would become possible. As a first step of this approach, in silico methods were used to model the structure of the complexes formed between the phosphorylation sites of the R-domain and the nucleotide-binding domain 1 (NBD1). Protein structure predictions were performed using AlphaFold-Multimer neural network, which is one of the currently available best methods for predicting the structure of protein complexes. Selected complex structures modelled by AlphaFold-Multimer were studied using molecular dynamics simulations. The models provide information about possible conformations of R-domain and NBD-1 complexes, thus contributing to the selection of target sites for the redesigned “miniproteins”.
Acknowledgements: This research was funded by the ÚNKP-22-2-III-BME-239 New National Excellence Program of the Ministry for Innovation and Technology, NRDIO/NKFIH grant numbers K127961, K137610, and Cystic Fibrosis Foundation (CFF) grant number HEGEDU20I0.
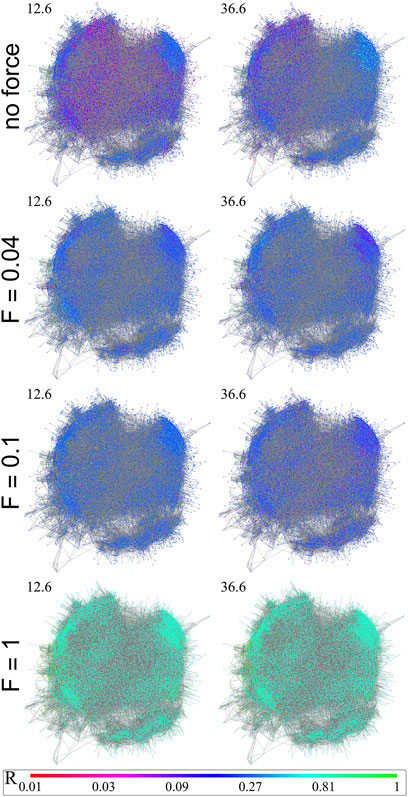
We have investigated the synchronization transition of the Shinomoto-Kuramoto model on networks of the fruit-fly and two large human connectomes. This model contains a force term, thus is capable of describing critical behavior in the presence of external excitation. By numerical solution we determined the crackling noise durations with and without thermal noise and showed extended non-universal scaling tails characterized by the exponent 2 < τt < 2.8, in contrast with the Hopf transition of the Kuramoto model, without the force τt = 3.1(1). Comparing the phase and frequency order parameters we have found different synchronization transition points and fluctuation peaks as in case of the Kuramoto model, related to a crossover at Widom lines. Using the local order parameter values we also determined the Hurst (phase) and β (frequency) exponents and compared them with recent experimental results obtained by fMRI. We show that these exponents, characterizing the auto-correlations are smaller in the excited system than in the resting state and exhibit module dependence.
Front. Phys. 11 (2023) 1150246. doi:10.3389/fphy.2023.1150246
In this talk, I will present my experiences building a range of Computational Fluid Dynamics applications on LUMI that use a variety of parallelization approaches, such as HIP, OpenMP offload, and SYCL. Given the relatively new AMD GPU platform, I discuss issues and limitations that affect development, debugging and performance analysis. I show a contrasting analysis of performance as a function of compilers and applications. For a few applications I also show and discuss strong and weak scalability up to 2000 GPUs and a problem size of half a trillion cells. Overall the MI250X GPU is a strong competitor to the NVIDIA A100 GPU given its raw performance, however there are still significant usability issues, making development challenging.
Laser induced fusion with simultaneous volume ignition, a spin-off from relativistic heavy ion collisions, was suggested, where implanted nano antennas regulate the light absorption in the fusion target [1,2]. Recent studies of resilience of the nano antennas in vacuum [3] and UDMA-TEGDMA medium [4] concluded that the lifetime of the plasmonic effect is longer in medium, however, less energy was observed in the UDMA-TEGDMA copolymer, due to the smaller resonant size of gold nanoantenna. Here we show how the plasmonic effect behaves in an environment fully capable of ionization, surrounded by Hydrogen atoms. We treated the electrons of gold in the conduction band as strongly coupled plasma. The results show that the protons close to the nanorod's surface follow the collectively moving electrons rather than the incoming electric field of the light and this screening effect is also dependent on the laser intensity.
[1] Csernai LP, Csete M, Mishustin IN, Motornenko A, Papp I, Satarov LM, et al. Radiation-Dominated implosion with flat target. Phys Wave Phenomena (2020)
[2] Csernai LP, Kroó N, Papp I. Radiation dominated implosion with nano-plasmonics. Laser Part Beams (2018)
[3] Papp I, Bravina L, Csete M, Kumari A, et al. Kinetic model evaluation of the resilience of plasmonic nanoantennas for laser-induced fusion. PRX Energy (2022)
[4] Papp I, Bravina L, Csete M, Kumari A, Kinetic model of reso-nant nanoantennas in polymer for laser induced fusion, Frontiers in Physics, 11, 1116023 (2023)
Making a given high-voltage power grid more stable and reliable has become a relevant question, especially when considering the current energetic situation or future development plans to augment and interconnect the existing network with renewable energy sources. Understanding the behavior and identifying the critical nodes and links of the network constructed from the power grid data, give us insight into possible ways to optimize its stability.
We investigate the European high-voltage power grid by not only considering the actual connections between the nodes but also calculating the edge admittances and weights based on the 2016 SciGRID project data. We perform community detection analysis and show the level of synchronization
on the 2016 European HV power grids, by solving the set of swing equations. By investigating these synchronization levels and communities, we identify critical nodes and links that play a key role in power transmission between different power regions and propose two ways to improve the synchronization level in the network.
The interplay of quantum and classical simulation and the delicate divide between them is in the focus of massively parallelized tensor network state (TNS) algorithms designed for high performance computing (HPC). In this contribution, we present novel algorithmic solutions together with implementation details to extend current limits of TNS algorithms on HPC infrastructure building on state-of-the-art hardware and software technologies. Benchmark results obtained via the density matrix renormalization group (DMRG) method are presented for selected strongly correlated molecules on model systems with Hilbert space dimension up to 2.8813e+36.
Following up on the similarly named talk in 2021, the evolution of standards in HPC haven't slowed down a bit. If anything, research and adoption have accelerated. There is a fair amount to be excited over around Khronos standards and open technologies.
While the compilation of quantum algorithms is an inevitable step towards executing programs on quantum processors, the decomposition of the programs into elementary quantum operations poses serious challenge, mostly because in the NISQ era it is advantageous to compress the executed programs as much as possible.
In our recent work [1] we proposed the utilization of FPGA based data-flow engines to partially solve one of these limiting aspects.
By speeding up quantum computer simulations we managed to decompose unitaries up to 9 qubits with an outstanding circuit compression rate.
However, the limit of the available resources on the FPGA chips used in our experiments (Xilinx Alveo U250) prevented us from further scaling up our quantum computer simulator implementation.
In order to circumvent the limiting factor of spatial programming on FPGA chips, in collaboration with Maxeler Technologies (a Groq\textsuperscript{TM} company) we found a novel use of the Groq\textsuperscript{TM} Tensor Streaming Processors (TSPs) which although used broadly for machine learning, they can also provide for a high performance quantum computer simulator. We prove that such data-flow hardware is indeed competitive for these particular problem sizes, being of practical importance and a subject of active research.
[1] Peter Rakyta, Gregory Morse, Jakab Nádori, Zita Majnay-Takács, Oskar Mencer, Zoltán Zimborás, arXiv:2211.07685
We present an improved efficiency Leading Zero Counter for Xilinx FPGAs which improves the path delay while maintaining the resource usage, along with generalizing the scheme to variants whose inputs are of any size. We also show how the Ultrascale architecture also allows for better Intellectual Property solutions of certain forms of this circuit with its newly introduced logic elements. We also present a detailed framework that could be the basis for a methodology to measure results of small-scale circuit designs synthesized via high-level synthesis tools. Our result shows that very high frequencies are achievable with our design, especially at sizes where common applications like floating point addition would require them. For $16$, $32$ and $64$-bit, our real-world build results show a 6\%, 14\% and 19\% path delay improvement respectively, enough of an improvement for large scale designs to have the possibility to operate close to the maximum FPGA supported frequency.
Leading Zero Counters (LZC [1] are of importance for various bit-level tasks, most notably floating point addition and subtraction [2, 3] such as in the IEEE-754 standard. In fact, a traditional clever use of floating point units (FPUs) addition/subtraction unit has been using the normalization process post-subtraction with custom byte-packing [4].
More formally, we define the LZC-n for bit-vector $X_{n..1}$ as an ordered pair $(V, C)$ where
$
V = \bigwedge\limits_{K=n}^{1} \overline{X_k} = \overline{X_n} \wedge \overline{X_{n-1}} \wedge \dots \wedge \overline{X_1}
$
is the all-zero signal and
$
z(i, j)=\left(\bigvee\limits_{k=n-2^{i+j}}^{n-2^{i+j+1}} X_k\right) \vee \left(\bigwedge\limits_{k=n-2^{i+j+1}}^{n-2^{i+j+2}} \overline{X_k} \wedge z(i, j+2) \right)
$ with \
$
C=\parallel_{i=0}^{\lceil\log_2 n\rceil-1} \left( V \vee \left(\bigwedge\limits_{k=n}^{n-2^i} \overline{X_k} \wedge z(i, 0) \right) \right)
$
represents the leading zero count as a bit-string (which is built via the concatenation operator $\parallel$) in Boolean algebra as an infinite recurring relationship (where $\vee$ and $\wedge$ are logical OR and logical AND respectively). In our notation, a bar above represents a logical negation and $\lceil x \rceil$ is the ceiling operation of rounding $x$ up to the nearest integer.
Although traditionally a focus on power is prevalent, we have chosen to focus on performance, then area and only minimize power if it does not effect performance or area. As higher area allows more concurrency and thus more performance, our justification for high-performance computing (HPC) is due to work in the area of Quantum simulation. But an investigation into the latest offerings for HPC in Ultrascale and Vivado is thus forthcoming.
Our contribution is thus a more general framework which uses careful and precise integration of a more modular framework, which yields a better result. Expert re-synthesis of integrated units of a modular design, can unsurprisingly yield a better state-of-the-art result. The exact ideas and optimizations used are important in a broader range of circuits.
We specifically offer an improvement over the method which Zahir, et al. introduced [5]. Their method used an LZC-8 consisting of 3 LUTs cascading into a LUT6-2 as a primitive for larger LZC units. By removing the cascaded LUT structure of their 8-bit LZC primitive which although necessary for a 7 or 8 bit LZC, turns out to be logic expandable and reducible into the 16-bit layer, the path delay can be significantly improved.
[1] Giorgos Dimitrakopoulos, Kostas Galanopoulos, Christos Mavrokefalidis, and Dimitris Nikolos. Low-power leading-zero counting and anticipation logic for high-speed floating point units. IEEE Trans. Very Large Scale Integr. Syst., 16(7):837–850, jul 2008.
[2] H. Suzuki, H. Morinaka, H. Makino, Y. Nakase, K. Mashiko, and T. Sumi. Leading-zero anticipatory logic for high-speed floating point addition. IEEE Journal of Solid-State Circuits, 31(8):1157–1164, 1996.
[3] Pallavi Srivastava, Edwin Chung, and Stepan Ozana. Asynchronous floating-point adders and communication protocols: A survey. Electronics, 9(10), 2020.
[4] Sean Eron Anderson. Bit twiddling hacks. URL: http://graphics. stanford. edu/ ̃ seander/bithacks. html, 2005.
[5] Ali Zahir, Anees Ullah, Pedro Reviriego, and Syed Riaz Ul Hassnain. Efficient leading zero count (lzc) implementations for xilinx fpgas. IEEE Embedded Systems Letters, 14(1):35–38, 2022.
Quadratic unconstrained binary optimization (QUBO) problems, including MAX-CUT as a special case, are important hard problems of mathematical optimization. Recently they have attracted much attention because they are the very problems that quantum annealers can address directly: QUBO problems are equivalent to the Ising model, a central and extensively studied problems in physics.
Even though the usefulness and efficiency of quantum annealers are subjects of many debates, their development is steadily going on. And the equivalence of QUBO and Ising models bridges between two different, well-developed approaches and insights to the problem: that of mathematicians and physicists. The former is based mainly on semidefinite relaxations or advanced cuts, whereas the latter offers a physical insight and includes DMRG/tensor network algorithms, classical and quantum annealing, or simulated bifurcation.
In the present talk we introduce the first railway application of quantum annealers that had been proposed partly by some of us. The railway dispatching / conflict management problem is addressed, which is equivalent to a job-shop scheduling with blocking and no-wait constraints. It is a computationally hard problem and the calculations have to conclude in a very limited time. We present
our proof of concept demonstration, described also by Domino et al. (Entropy vol. 25, 191 (2023)) based purely on quantum annealing, but calculated alternatively also on classical computers with tensor network algorithms (c.f. Rams et al., Phys. Rev. E vol. 104, 025308 (2021)). and with brute-force method on GPUs (Jałowiecki et al., arXiv:1904.03621v2 (2019)). We also present our ongoing work where we show that hybrid quantum-classical heuristics are valid and practically useful options in dealing with such a problem. We describe modeling strategies, benefits and limitations of quantum annealing approaches.
To illustrate one of the limitations of quantum annealers in detail, we discuss deeper the problem that that as most heuristics they do not necessarily find the optimum. We briefly present a probabilistic discriminator based on statistical physical ideas that can indicate whether the optimum was found (c.f. Domino et al., Quantum Information Processing vol21, 288 (2022)) . We also consider the standard (Fortet) linearization of a QUBO, and, as a mathematical approach, discuss the possibility of using MILP duality for the purpose of deciding whether an optimum was found. The latter approach is a general one, not specific to quantum annealing.
Finally discuss the perspectives of hybrid (HPC+quantum) solvers, and the potential benefits from using physics-motivated algorithms for solving QUBOs in general.
Closed quantum systems are described by a deterministic, linear evolution of their quantum states. Observation of a system breaks this rule: we gain information and the description becomes probabilistic. Provided we have multiple copies of a system in the same quantum state, we can design a protocol consisting of a joint unitary operation on all of them and a subsequent measurement on all but one of the outputs. Accepting only certain measurement outcomes, we arrive, in general, at a nonlinear quantum transformation on the remaining system. These nonlinear quantum transformations play an important role in quantum state distillation, aiding quantum communication schemes. We consider such iterated nonlinear protocols for qubits, involving a generalized CNOT, a measurement, and a single-qubit Hadamard gate processing n inputs in identical quantum states. In our work, we study the asymptotic properties of this special class of iterated nonlinear maps using numerical methods. We determine the fixed points, relevant fixed cycles and show the presence of a universal phase transition related to the disappearance of the fractalness of borders of different basins of attraction. The transition point is marked by a repelling fixed point, which has an increasing purity, tending to 1 as we increase the order n of the map. The generalized Julia set, defined as the set of border points between the basins of attraction for fixed purity initial states, has a constant fractal dimension as a function of the purity, above a critical value. Remarkably, we found that this fractal dimension is universal in this family, it is independent of the order n of the map.
The GigaBit Transceiver (GBT) and the low power GBT (lpGBT) link architecture and protocol have been developed by CERN for physical experiments in the Large Hadron Collider as a radiation-hard optical link between the detectors and the data processing FPGAs (https://gitlab.cern.ch/gbt-fpga/). This presentation shows the details of how to implement a large array of GBT/lpGBT links (up to 48 x 4.8/5.12/10.24 Gbps) on a custom data acquisition board based on the Intel Arria 10 FPGA.
GUARDYAN (GpU Assisted Reactor Dynamic ANalysis) is a GPU-based dynamic Monte Carlo code developed at Budapest University of Technology and Economics. As an emerging calculation technology, dynamic Monte Carlo computes the neutron population evolution by calculating the direct time dependence of the neutron histories in multiplying systems. GUARDYAN targets to solve time-dependent problems related to fission reactors with the main focus on simulating and analyzing short transients. The key idea of GUARDYAN is a massively parallel execution structure making use of advanced programming possibilities available on CUDA enabled GPUs. The GUARDYAN has been recently coupled with SUBCHANFLOW subchannel thermal-hydraulics solver to carry out dynamic calculations with thermal-hydraulics feedback. The coupling is compared against other dynamic Monte Carlo-based neutron transport codes (SEPRENT, TRIPOLI-4) with SUNCHANFLOW coupling in TMI 3x3 transient scenario. The results of the comparison showed an exact match.
The recent rapid development in the generative methods of artificial intelligence makes it more and more urgent to understand, what is the intelligence they manifest, what are the limits and where are the breakthrough points for a next generation AI. In the talk we examine, what is the relation of the present-day leading AI applications to human thinking, in particular the "fast" and "slow" thinking (System 1 and System 2). We try to suggest a way to make the AI applications more controlled and more conscious.
Some applications of Monte Carlo simulation require the generation of a
large number of small grids of bits (e.g. tiles or boards of 32 by 32 bits) with a
given number of bits set to one, the rest is set to zero. Conventional sequential
algorithms generate them by randomly selecting empty sites until the given
number of set sites is reached, which is not an efficient solution. In this talk
we present a solution that uses the special capabilities of either CPU or GPU
to generate them at a high speed. In the CUDA implementation the tiles are
generated warpwise (with the use of warp shuffles) thereby eliminating the loop
divergence of threads. This realization allows us also to reduce the use of shared
memory, the computation is performed in registers, only the PRNG states are
stored in local memory.
In this talk, we will describe our experience with the GPULab cluster in accelerating EEG signal processing and data analysis. GPULab is a large GPU computing resource of IMEC (Belgium) accessible for researchers through the SLICES-SC research infrastructure project. The system consists of a set of heterogeneous clusters, each with their own characteristics (GPU model, CPU speed, memory, bus speed, etc.), allowing users to select the most appropriate hardware. Jobs run isolated within GPU-enabled Docker containers with dedicated CPUs, GPUs and memory for maximum performance.
Our goal is to develop a GPU-accelerated EEG processing pipeline that significantly reduces execution time of large scale EEG data analysis tasks. The 16-GPU HGX-2 (V100 based) GPULab node is especially suited to our planned multi-GPU development effort. We are working on the implementation of high-performance, massively parallel algorithms for EEG preprocessing steps (filtering, artefact removal, baseline removal, averaging), power spectral density estimation, various transforms (Fourier, Wavelet, Hilbert, etc.) and signal decomposition methods (Independent Component Analysis, Empirical Mode Decomposition, etc.). We are studying advanced algorithmic and technical solutions (communication avoiding algorithms, mixed-precision computing, tensor cores, in-kernel multi-GPU communication, etc.) to achieve high levels of scalability even on extreme scale supercomputers.
In the talk, we will describe the GPULab infrastructure, its access modes to users, the containerised software environment, and our experience with the system. We will also describe results of our multi-GPU performance testing and the potential factors affecting application performance, as well as show the current status of our EEG algorithm development work.
The cloud-based GPULab infrastructure has great potential for accelerating data-intensive computational jobs, and gave us the opportunity to carry out preliminary multi-GPU algorithm development. However, research on the scalability of large-scale multi-GPU EEG data analysis algorithms will require future work on peta- and pre-exascale supercomputers.
The Artificial Intelligence National Laboratory Hungary (MILAB) is a research consortium of 11 institutions in Hungary. MILAB researchers use GPUs to accelerate the training of deep neural networks for machine vision tasks in object detection, surveillance and medical imaging applications. We train and evaluate deep neural networks for natural language processing tasks, such as sentiment analysis, NER, and text summarization, in particular for the development of the HuSpaCy system. We also use GPUs to train and evaluate deep reinforcement learning models for robotics applications, such as autonomous navigation and manipulation.
Proton therapy is an emerging method against cancer. One of the main developments is to increase the accuracy of the Bragg-peak position calculation, which requires more precise relative stopping power (RSP) measurements. An excellent choice is the application of proton computed tomography (pCT) systems which take the images under similar conditions to treatment as they use the same irradiation device and hadron beam for imaging and treatment. A key aim is to develop an accurate image reconstruction algorithm for pCT systems to reach their maximal performance.
An image reconstruction algorithm was developed in this work, which is suitable to reconstruct pCT images from the energy, position and direction measurement of individual protons. The flexibility of an iterative image reconstruction algorithm was utilised to appropriately model the trajectory of protons. Monte Carlo (MC) simulations of a Derenzo and a CTP404 phantom was used to test the accuracy of the image reconstruction. We used an averaged probability density based approach for the interaction (system) matrix generation, which is a relevant description to consider the uncertainty of the path of the protons in the patient. In case of an idealised setup 2.4~lp/cm spatial resolution and 0.3\% RSP accuracy was achieved. The best of the realistic setups results 2.1~lp/cm spatial resolution and 0.5\% RSP accuracy.
Proton therapy is a promising method for cancer treatment, where the energy deposit may be focused on the cacerous cells, hence providing a much faster method with less side effects as a traditional radiation therapy. However, a good diagnostic tool, a "CT" with ptotons is missing to reach the desired accuracy. Here, we model a new tool chain, where we generate events, detected by the planned detector for various phantoms, identifying trajectories and the energies and direction of the charged particles behind the phatom. The information extracted is the input for image reconstruction algorithms. Due to the complexness of the identification we designed neural network based models to speed up the process.
The application of deep learning in gigapixel whole slide image analysis has shown promising results in terms of accuracy and efficiency compared to traditional image analysis techniques. Transformer based models as the current state-of-the-art algorithms are capable of identifying and classifying various structures and patterns within the tissue, providing insights into the underlying pathology and helping in the diagnosis and treatment of diseases. However analyzing pathological whole slide images with vision transformers requires specialized hardware with high computational power, high-speed memory and interconnects. High-performance GPUs and TPUs are commonly used for this purpose, as they are designed specifically for processing large amounts of data in parallel. In this presentation we demonstrate an efficient pipeline for image preprocessing and application of deep learning models at TB scale for digital histopathology.
Position control is a fundamental task of mechatronics, where the goal is to drive an object to a desired position or maintain its trajectory on a given path. The digital implementation of control leads to a sampled-data system, resulting in piecewise smooth dynamical properties due to the sudden changes of the control input at the sampling instants. In the controlled mechanical system, dry friction causes another nonsmooth effect because the Coulomb-friction force has a jump discontinuity at motion reversals. These two phenomena appear simultaneously in a mechatronic system; however, the sampling and friction-caused switchings are independent, making the analysis difficult.
In this work, the position control of a single-degree-of-freedom (1DoF) system in presence of friction is presented with an iterated function system (IFS) based approach. An IFS consists of a finite number of mappings on a metric space primarily used to describe fractals. We present that the discrete-time model of the discussed 1DoF nonsmooth system can be transformed into an IFS on the system's state space.
The numeric evaluation of the IFS can be challenging because a large set of initial states must be examined to describe the system accurately. To address this problem, we present a GPU-based simulation implemented in OpenCL to parallelize the function evaluations.
Supported by the ÚNKP-22-3-1-BME-336 New National Excellence Program of the Ministry for Culture and Innovation from the source of the National Research, Development and Innovation Fund.
In HPC, a common method is decomposing large equation systems into a batched
problem of small equation systems. Such small systems are
Tridiagonal/pentadiagonal matrix systems frequently arise in
finite-difference methods for solving multi-dimensional PDEs in various
applications. Such systems are, for instance, present in computational fluid
dynamics (CFD) for flow solvers based on implicit high-order finite-difference
schemes, like the Alternating Direction Implicit (ADI) method. In this talk, I
will present our initial results of developing a scalable batch-pentadiagonal
solver library for large CPU and GPU clusters for ADI applications. We use the
hybrid Thomas-Jacobi and Thomas-PCR algorithms using the Thomas algorithm
locally to create a reduced system and a distributed solver on the reduced
system. We show the cost difference between the local communications of the
approximate solver (Jacobi) and the one-to-one communications with increasing
distance of the exact solver algorithm (PCR). We show the scaling behavior of
these algorithms on LUMI up to 1024 GPUs in one direction.
Examining the dynamics and spatial properties of individual stars and stellar populations in satellite galaxies surrounding the Milky Way through the lenses of galactic archeology is crucial to understand galactic evolution. By gaining insight into this process, it can provide us valuable information about the large-scale and long-term characteristics of both ordinary matter and dark matter. Thorough studies can utilize both photometric and spectroscopic observations that complementarily support each other. Here we focused on the spectroscopic aspect of this problem, by investigating how well autoencoder-based neural networks (AEs) perform in the processing and analysis of stellar spectra. We show that AEs are capable of learning the characteristics of a stellar spectrum to a considerable extent, even in noisy and low $S/N$ conditions. Moreover, they can be extremely valuable tools during the preprocessing stage of spectroscopic data analysis, where otherwise finding the black body continuum of a noisy spectrum is challenging.
PyTorch is a production-ready framework for machine learning in
Python, offering a robust ecosystem and a large community behind. It
takes advantage of GPUs, HPC, and cloud environments. While primarily
aimed for machine learning applications, it includes tools for a broad
area of numerical applications, including, e.g. linear algebra,
tensors, random numbers, statistics, optimization, etc. In spite of
that the coverage of methods and the structure of the package is
strongly aimed at ML applications, it has potential applications in
many other fields. The benefits of such an approach include the
possibility of exploiting extensive computer resources via codes that
are simply and quickly developed in Python.
In this talk I present in detail a PyTorch-based example of graph
coloring using the stochastic gradient descent (SGD) algorithm in
order to demonstrate such a use case. While the primary use of SGD and
its modified versions in AI is to optimize neural network parameters
during the “training” phase, the user can also use SGD to minimize a
custom objective function if it can be defined within the PyTorch
framework.
The objective function of our example is defined as follows. Let $A$ be
the $m\times m$ adjacency matrix of a finite, loopless planar graph. Let $C$ be
an $m\times n$ matrix, where each row represents a vertex and each row vector
is a one-hot encoded color vector candidate. Then the objective
function to be minimized w.r.t $C$ is
$$L(C)=\sum \sum \left[ C C^\top \circ A\right]$$
As for the algorithm, initially, fill $C$ with i.i.d. random
numbers. Then we apply row-wise softmax normalization after each
update on $C$ to ensure one-hot encoding for row vectors. The
presented algorithm is heuristic as it does not guarantee convergence
to an optimal coloring. Yet it demonstrates the simplicity of
implementing such an algorithm with PyTorch.
The searching for ephemeral liquid water on Mars is an ongoing activity. After the recession of the seasonal polar ice cap on Mars, small water ice patches may be left behind in shady places due to the low thermal conductivity of the Martian surface and atmosphere. During the southern summer, these patches may be exposed to direct sunlight and warm up rapidly enough for the liquid phase to emerge.
A manual analysis on the screen was conducted on 110 images captured by the High Resolution Imaging Science Experiment (HiRISE) camera onboard the Mars Reconnaissance Orbiter space mission. Out of these, 37 images were identified with smaller ice patches, which were distinguishable by their brightness, colour and strong connection to local topographic shading. The seasonal occurrence of these patches range between 140° and 200° solar longitude, in geographical location in the latitude band between -40° and -60°, with having diameters ranging from 1.5-300 meters.
In this study, a convolutional neural network (CNN) is applied to find further images with potential water ice patches in the given latitude band. Previously analysed HiRISE images are used to train the model, each chunked into hundreds of pieces, significantly expanding the dataset. Using a CNN model makes it realistic to analyse all available surface images, aiding us in selecting areas for further investigation.